To follow up on Jack's post here, I ran a search of Historical Presents using Dr. Runge's LDGNT and comparing it with the new Grammatical Construct dataset. First the searches:
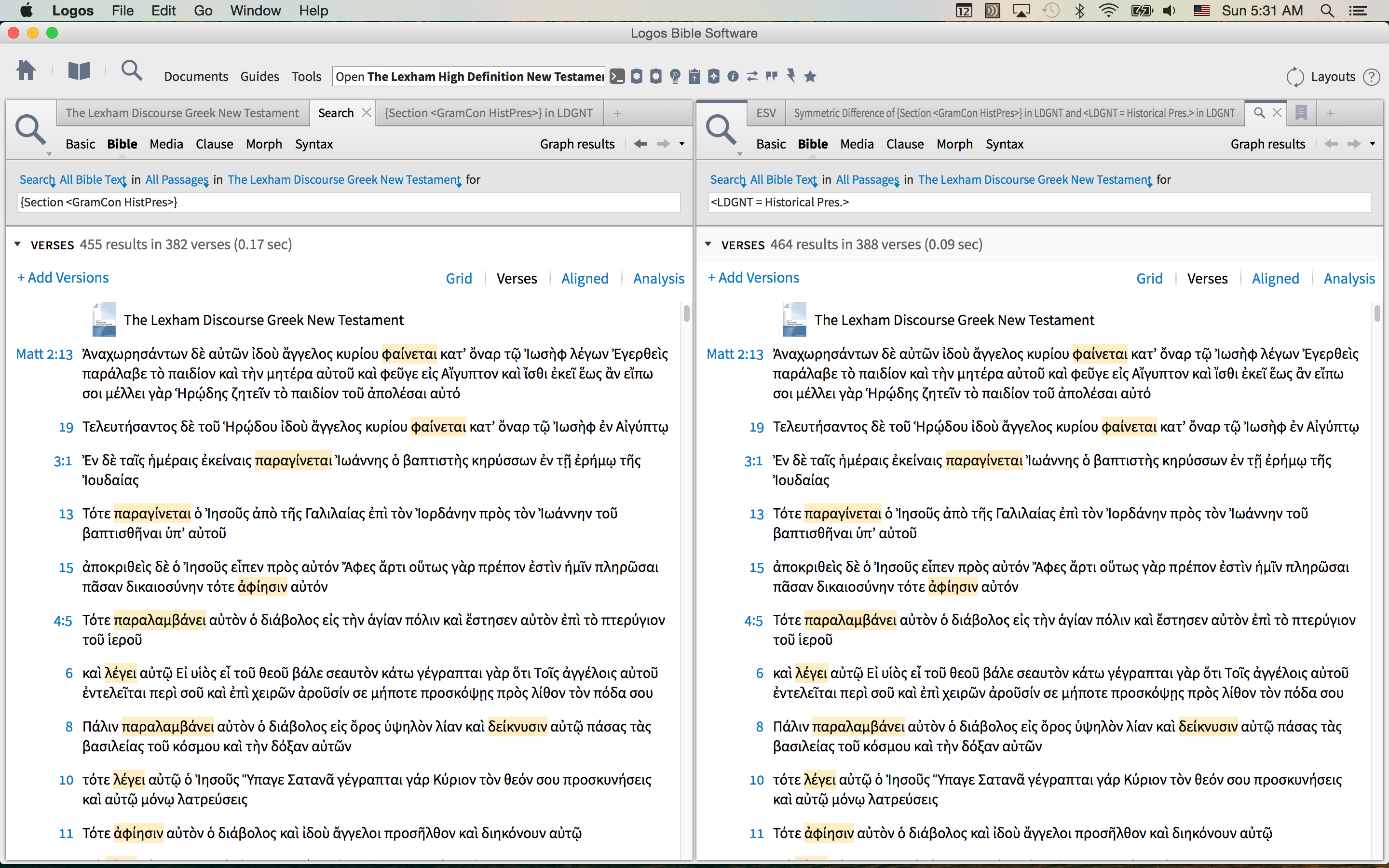
Note there are 6 verses that are different using the same text.
Now the passage list comparison:

So here are the 6 verses. Please comment as to why the two separate searches are resulting in differences? to Jack's point, the user needs to : 1. understand the dataset and 2. be able to rely on the dataset. These differences create some confusion and question accuracy of the data.






