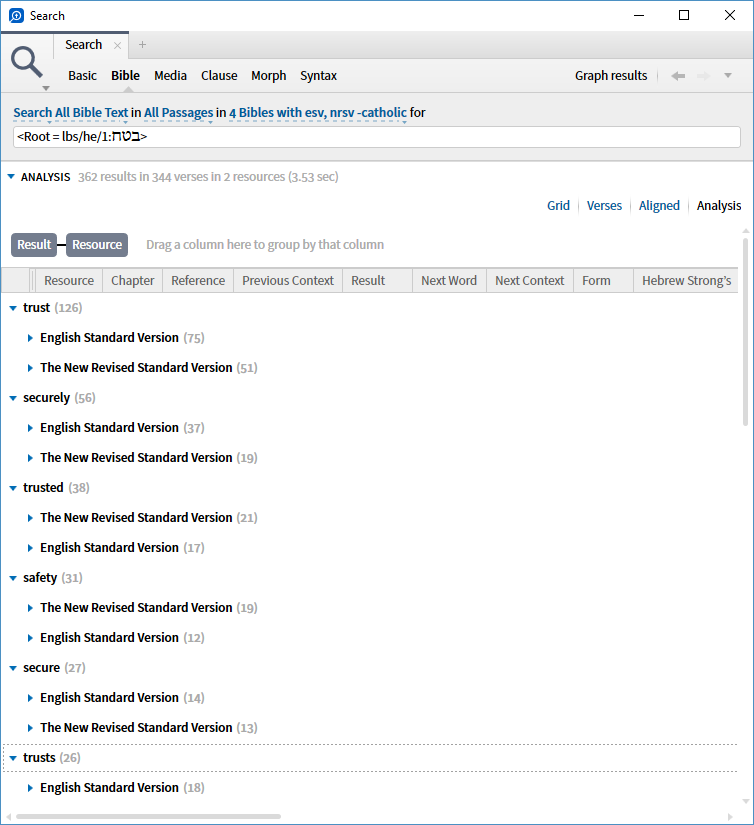
Which leads to a question that perhaps many would be interested in: what are Faithlife's quality control procedures for resource tagging?
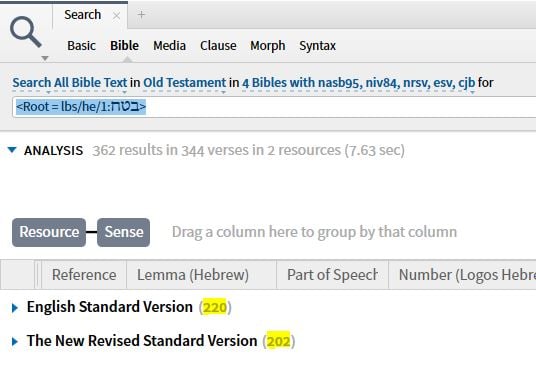
The issue appears when you apply "Sense" as a grouping term - without it you get the same number of root matches in each translation
and the difference is due to a variance in untagged senses with the first difference being Deut 33:12 having a sense tagged in NRSV but seemingly not in ESV
Looking further down in ESV, however, it is tagged
The difference is that two words are combined in ESV
whereas just one word is tagged in NRSV
I assume, but haven't checked, that something similar is happening in the other cases.
Hopefully this will help in tracking this inconsistency down.
This issue is nothing to do with quality control, but with the vagueries of running an original language query on a variety of translated Bibles. As Graham's research shows, it's inevitable that there will be inconsistencies — not because the tagging is inadequate, but that it is necessarily approximate when applied to English-language Bibles.
Which leads to a question that perhaps many would be interested in: what are Faithlife's quality control procedures for resource tagging? This issue is nothing to do with quality control, but with the vagueries of running an original language query on a variety of translated Bibles. As Graham's research shows, it's inevitable that there will be inconsistencies — not because the tagging is inadequate, but that it is necessarily approximate when applied to English-language Bibles.
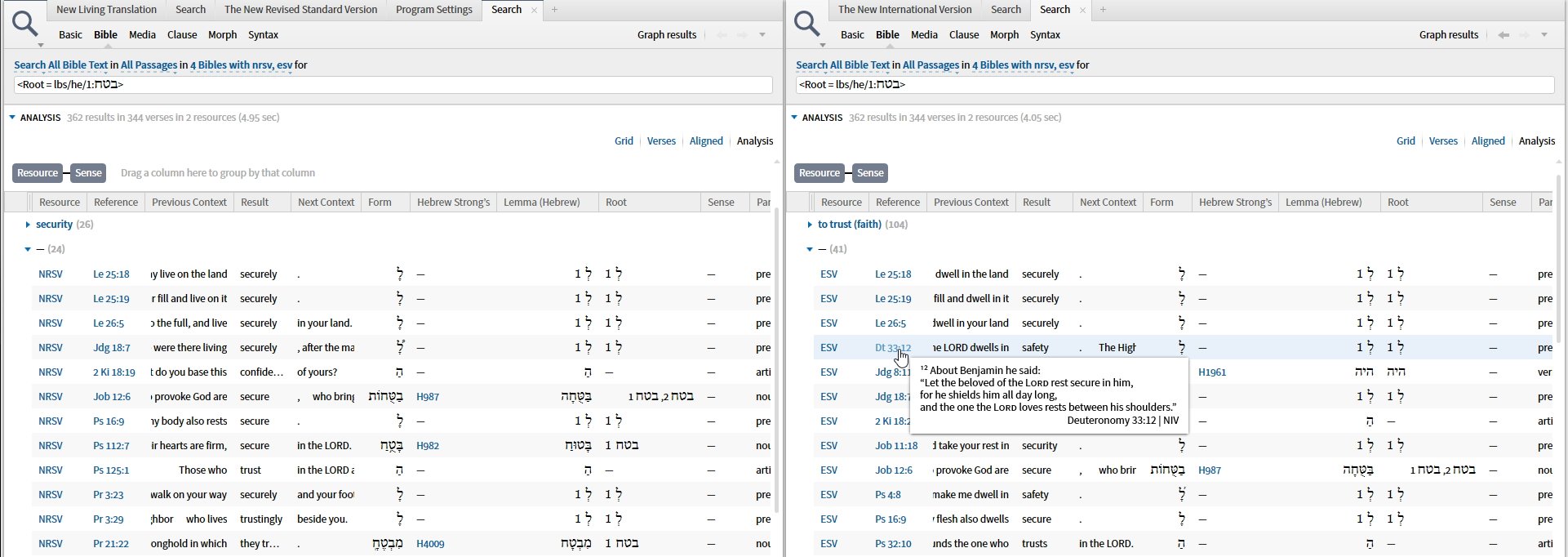
but the Hebrew is the same and the English is the same for both translations. Logos did the linking between the texts. One time they decided to leave the "in" out of לבטח and one time they decided to include it. Note also the inconsistent direction of the arrows in ידיד ה'.
I understand that for this specific example (although neither is wrong, they're just different). But that doesn't change the principle that using English-language texts for original-language encoding is inevitably going to bring up approximations. You simply shouldn't compare results across English-language Bibles when searching using original-language data.
Graham used the first example. Let's look at the second, from Judges 8:11, the ESV has "felt secure" (3 results because of the way the RI works), whereas the NRSV has "was off its guard" (one result). That's not inconsistent tagging, that's just the reality of reverse interlinears.
There is no inconsistency in this second example you brought but the first example shows inconsistency. What if Logos was also inconsistent in treating the same phenomenon in several occurrences of the same resource? Suppose I make a reverse search on the Septuagint for instance, and the linking was done in an inconsistent manner, the results of the search would be worthless.
I'm not trying to argue that there aren't inconsistencies in Logos' data, and that it would be good to eliminate those inconsistencies (exhibit 1).
I'm simply saying that the search presented in the original post doesn't prove those inconsistencies.
If the OP post was "Inconsistent RI tagging in the ESV/NRSV in Deut 33:12", I'd obviously have responded differently. But the original post was to do with "root tagging", and specifically lining up root tagging in reverse interlinears. These searches will never be reliable and was never intended to be reliable.
[Y]
You simply shouldn't compare results across English-language Bibles when searching using original-language data.
You should when the nature of what you are doing requires you to do so, namely, here, to compare how the same root is rendered across English translations and be able to express these results in terms of statistics.
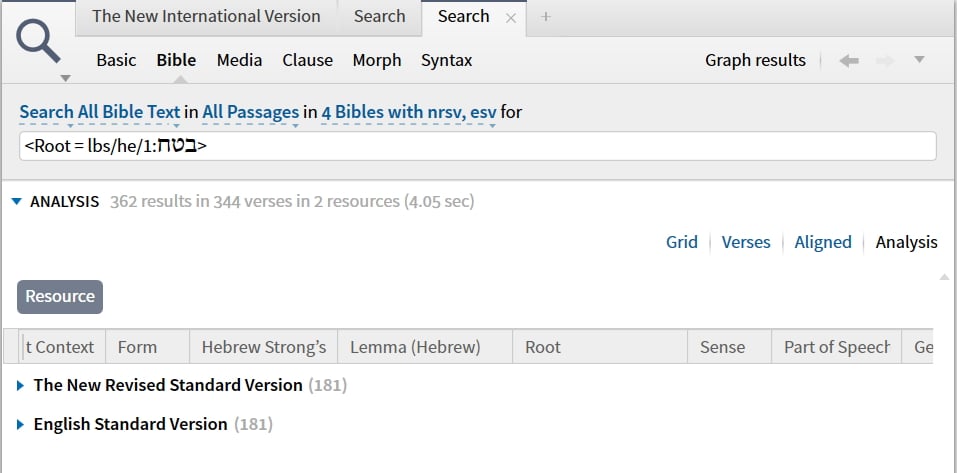
Although Graham's explanation is useful, but I still find curious, considering that my search term was the root, not senses, that the number next to the resources should NOT correspond to the number of hits for the root. After all, sorting is not adding a limitation to the search, but organising the results into subcategories. So when I look at the stats of the top category, it should correspond to what this would be if I only searched for that only (e.g., batach in the ESV), not a total derived from the subcategories with the problems that can result.
To illustrate further the confusion that results: if I only organise by resource, I get 181 hits for batach in the ESV. If I subcategorise by sense, then the number next to "ESV" jumps up to 220. How are we to interpret this number? Well, since it is the total of the senses below, we may call it "the number of different senses batach has in the ESV." But now we have another problem: we have way 39 mores senses than the root occurrences they are supposed to render!
But comparing sense data won't help you with that, because this data is created from the original language texts. It will take into account textual differences, but not translation differences. That's partly my point.
Although Graham's explanation is useful, but I still find curious, considering that my search term was the root, not senses, that the number next to the resources should NOT correspond to the number of hits for the root.
When you're searching RIs, the number of hits returned is the number of hits in the surface texts (another reason not to use RIs for statistics). When a single sense stretches across two English words, that will produce two hits. Roots and senses will sometimes 'stretch' differently, and that's why the numbers vary.
The best way you can do that is like this:
The alternative would be to use the BWS wheel for each of the lemmas within that root.
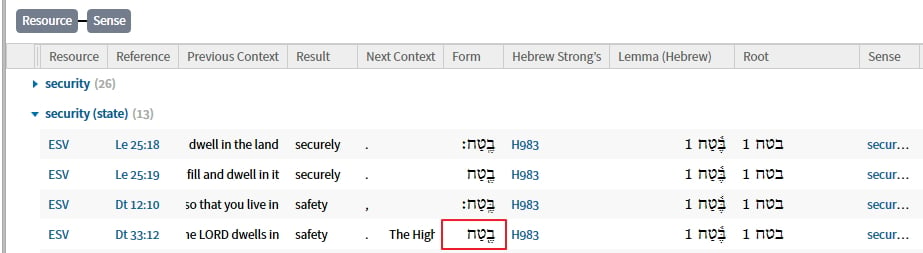
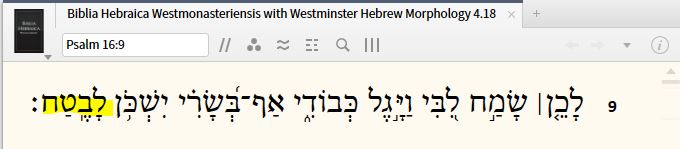
Here is the problem. Consider Ps 16:9
Both the root itself and the attached preposition are listed and counted separately as a distinct instance of a sense:
Since I was searching for the root, and not for the preposition, the latter should not be listed in the results. And it is incorrect to say it has that sense, of which the value is null (listed as "--"). Either it is thought of as a unit with the noun (one sense for both together) or as having a sense of its own which is not null. Either way, this does not work and is incorrect and messes up the number of hits.
I understand that "a single sense stretches across two English words" which is precisely the case here. But we have to make our mind here as to what is being searched (the root in the surface text). The search started with the root, not the sense. If I searched the sense first and sorted it by root, I understand that batach and le should both be listed. But I searched for batach, then looked for the sense for batach, yet it still shows me a sense for le.
But we have to make our mind here as to what is being searched (the root in the surface text).
But we have to make our mind here as to what is being searched (the root in the surface text). The search started with the root, not the sense
I understand the point you're making. Believe me.
But I'll say it again. Analysis searches on reverse interlinears will never return 100% accurate results because of the way reverse-interlinears work, and because of the limitations inherent in searching them. They are not intended to return 100% accurate results, for that use original language texts. It's a known limitation that we've all got to live with.
See this quote from Bradley:
Morph Search analysis is designed to work on an original language resource. Running it on a reverse interlinear will work for the most part, but you will get unexpected output from the locations where multiple Hebrew (or Greek) words are translated by one English word (or by a phrase, idiomatically).
And read this discussion: https://community.logos.com/forums/p/67304/469075.aspx#469075 (particularly Bradley's comments below mine).
But I searched for batach, then looked for the sense for batach, yet it still shows me a sense for le.
This is because you're searching the Hebrew text as it is aligned to an English translation. The granularity of the results is controlled by the alignment units in the RI; when multiple lemmas are aligned to a single English word/phrase, all the information from those lemmas will be mixed together into the Analysis grid.
It seems like what you want to do is: find all instances of a root (in the Hebrew), group them by sense, and only then, align to the English. This is an good feature suggestion for the Analysis grid (i.e., search in LHB then add one or more "Translation" columns after the search has run, similar to adding parallel resources in the "Verses" view of Bible Search) but is not currently supported.
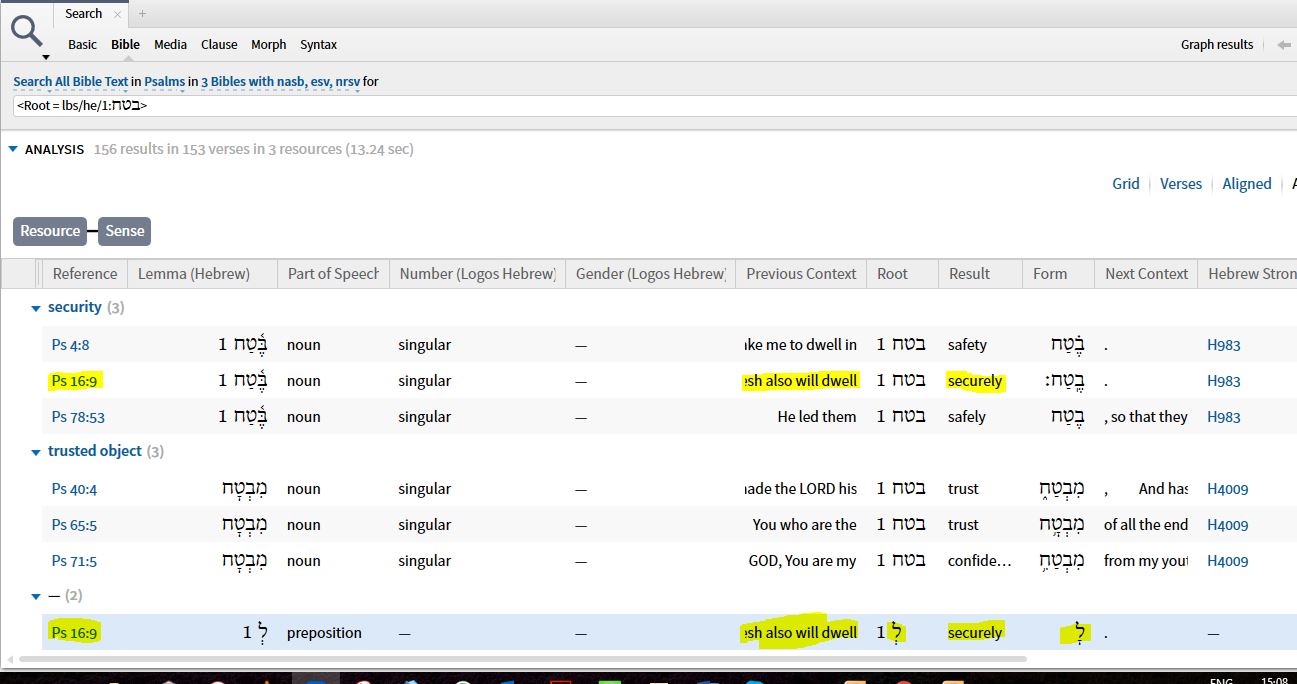
I noted also that in your suggestion, you reversed the order when you substituted Result for Sense (you have Result-Resource instead of Resource-Result). In the latter case, the problem is the same: there are 52 hits in the ESV in Psalms when sorted only by Resource, but 59 when sorted by Resource-Result (the definite article is counted as a hit). In the following example, Ps 125:1 in the NASB, the definite article is translated as "those" in the interlinear. In fact, right-clicking on "trust" in the English text only links it to the root with no mention of the article at all. Why it appears as a "result" in the analysis I still cannot fathom:
EDIT: I posted this before I saw your replies Mark and Bradley. I cannot say that they completely solve it for me. Perhaps the simplest answer is as Mark puts it "a limitation inherent to how the reverse interlinear works" which accept them as they are designed.
Why it appears as a "result" in the analysis I still cannot fathom:
The result in the grid you're showing in the screenshot is from the ESV or NRSV, not the NASB. If you look at one of those translations, you'll see that both lemmas are aligned to a single unit "Those who trust", which is why they both appear in the grid.
Perhaps the simplest answer is as Mark puts it "a limitation inherent to how the reverse interlinear works" which accept them as they are designed.
Yes, this is how searching in reverse interlinears works.
The result in the grid you're showing in the screenshot is from the ESV or NRSV, not the NASB.
Right, since I was under a specific resource, I assumed the link would open in it when I clicked on it but it used my default English Bible instead, and then I thought it must have been under that resource. My mistake here. It does bring up the question of consistency again though: why is "those who trust" (the exact same English rendering for the exact same Hebrew underlying text) one unit in ESV but not in the NASB?
Available Now
Build your biblical library with a new trusted commentary or resource every month. Yours to keep forever.