Due to a project that I'm involved with, I wanted to create Visual Filters for all the reported speech in Genesis by the speaker. I realize that this data tagging is not simply straightforward (e.g. embedded reported speech would necessarily(?) have two speaker tags; the one speaking and the one being quoted). The problems were far more prolific than this, however, and I gave up on using a VF. Below is a simple example:
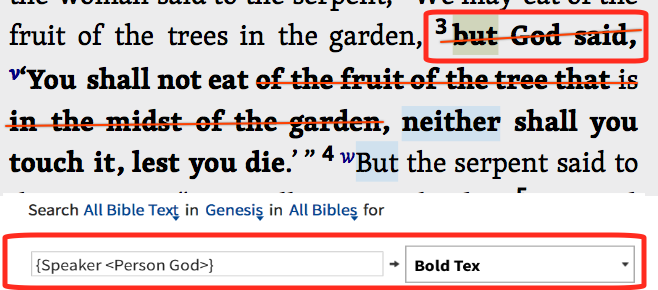
If this tagging is based on the English text, then it's super obvious that "but God said" is Eve speaking, and not God.
If, however, it is based on LHB as I assumed, then it's even worse. As I read the Hebrew text, the parts I've struck through in the screenshot are only Eve speaking (in other word's she's not purporting to quote God or even to report what he said here).
This data needs to be seriously cleaned up. In addition, it should be more robust. In this example, none of the verse should have been a hit unless I had something like {Speaker-Quoted <Person God>} or perhaps {Speaker-Reported <Person God>} which to my knowledge doesn't exist. Am I missing something?


