I find it surprising that searching on a Greek or Hebrew word you must enter the exact diacritical marks.
For example, you cannot search for h:מלך and find a word that has these consonants, regardless of the vowel points.
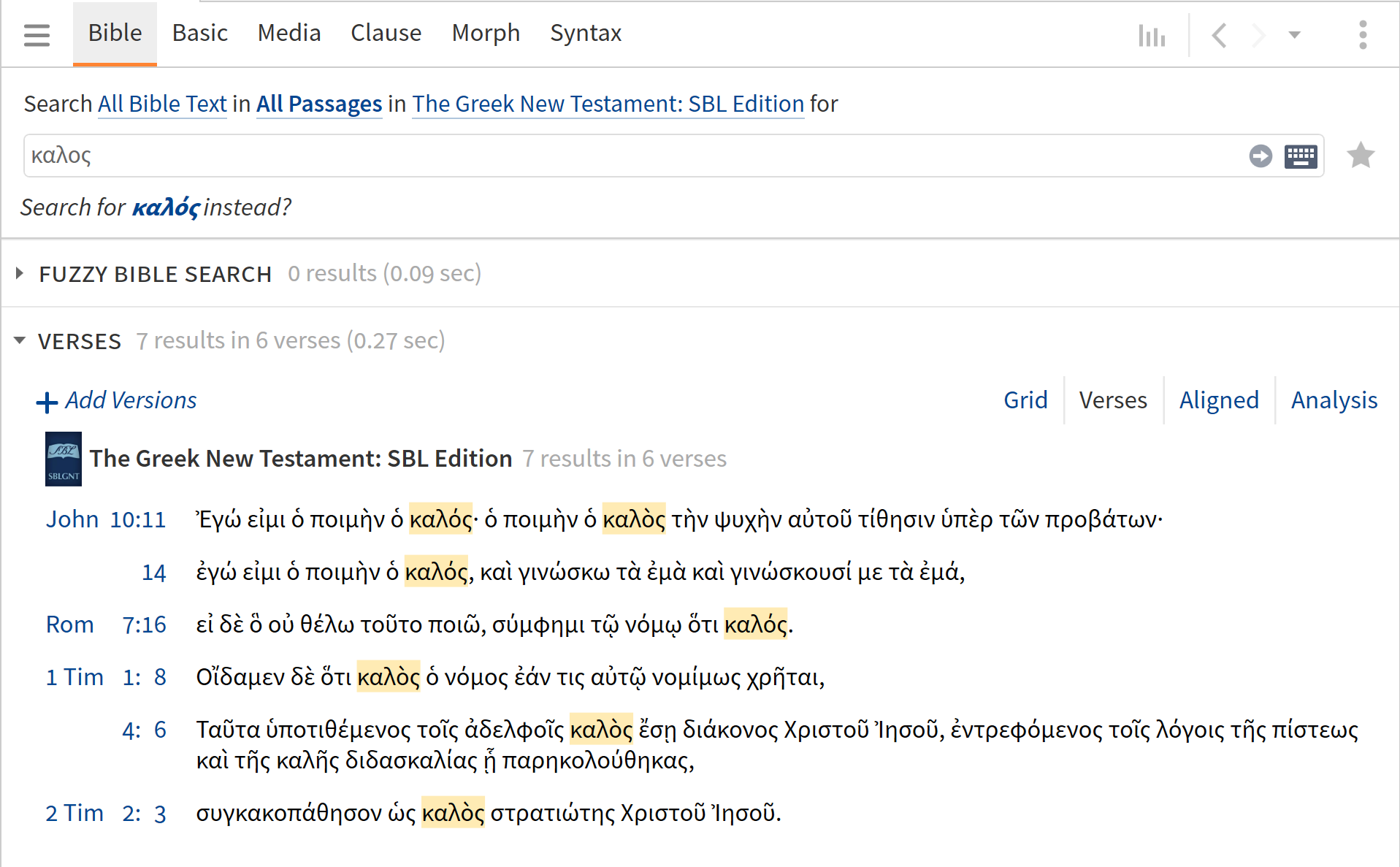
Accents in Greek words can change depending on the word that follows in a sentence. (e.g. an acute accent changes to a grave at the end of a word coming immediately before another accented word). For example, καλὸς and καλός mean the same thing and are in the same case, gender and number. Here is an example from John 10:11 where both καλὸς and καλός are found:
Ἐγώ εἰμι ὁ ποιμὴν ὁ καλός. ὁ ποιμὴν ὁ καλὸς τὴν ψυχὴν αὐτοῦ τίθησιν ὑπὲρ τῶν προβάτων.
In both instances the word means the same thing and functions as an adjective modifying the same noun ποιμὴν. The only difference is that καλὸς at the end of a sentence and καλὸς does not.
The odd thing is that the Logos search seems to ignore the accent, even though it must be entered. Searches for καλὸς and καλός both find the same verses.
If Logos ends up ignoring the accents, why require that accents be entered? Why not just allow a search for greek:καλος? It would much faster to enter either with a system Greek keyboard or the new Logos built-in Greek keyboard. I realize that words can be chosen from a pick list, but that is often slower than typing the word.
My preference would be that Logos ignore Greek accents, Hebrew vowel points and other diacritical marks, unless they are explicitly entered in the search.
Alternatively there could be an option on the panel menu such as "match diacritical marks". It could be greyed out except when entering non-English words, although the ability to search for or ignore accents and punctuation would be useful in English as well (particularly with loan words). Other Bible programs have allowed entering searches without exact accents and diacritical marks for decades.