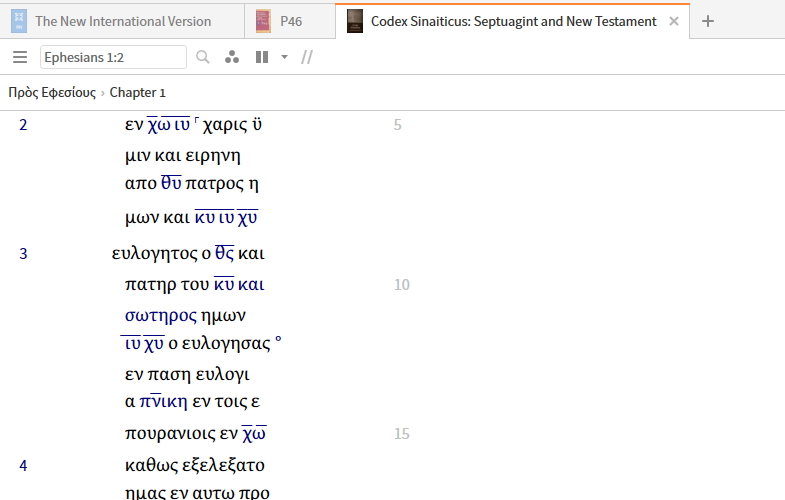
Is it possible to create visual filter for end of sentence according to the original language? e.g. One can see the break at Eph 1:2, 14, etc.
I'm not quite sure what you are looking for. There was no punctuation in the original text
That's exactly why this is tricky.
So the point is the concept of a sentense still exists, and although that could vary upon interpretation (what doesn't?), somehow someone got to decide how to chop it up.
Some sort of dataset (manual tagging) probably is needed somewhere at some point. But the question is if that dataset + tool to do this already exists.
For a decade I've been trying to create my own manual highlight in my favorite Bibles to highlight this. But it never gets finished and is Bible specific (sometimes I highlight 2 versions at a time, one Chinese, one English.) So if this could be done as a visual filter then it would be great. If not, I'll continue to manual highlight this and see if I die first or the Bible ends first.
So the point is the concept of a sentense still exists, and although that could vary upon interpretation (what doesn't?), somehow someone got to decide how to chop it up. Some sort of dataset (manual tagging) probably is needed somewhere at some point. But the question is if that dataset + tool to do this already exists.
The point is that a text Search does not concern itself with grammatical terms, so a Visual Filter is not possible.
If you want to know about, and search for, sentence breaks, then type Clause Visualization are your resources, and Syntax Search is your tool.
Then its a deficiency of the visual filter, not the question though. Isn’t it? The goal is simple and well defined and there just to be some way to make it feasible.
Note that this may be an example why an API to interface with Logos is useful. Having a full programming language free one to do things Logos tool might not be able to do just yet. See another thread for the suggestion of providing such API. (Sorry no link as I’m on mobile)
Then its a deficiency of the visual filter, not the question though. Isn’t it?
It's technically a search issue not a visual filter issue - we can't search on punctuation as it is not indexed.
The goal is simple and well defined and there just to be some way to make it feasible.
As I understand it this would be a significant change.
That's why I haven't raised it question a decade ago, but instead chose to manually highlight.
I guess the information is already there is some of Logos' datasets (or even as rudimentary as getting a search of period from some resource known to reproduce sentence boundary as close to original language as possible, including some original language Bible recourses.)
So this challenge is to reinforce having a full programming language to interface with Logos can free someone from limitations of what given tools might be able to give you. (I open this thread with this in my mind, but don't want to sound like dump if current Logos capability already cover this.)
I didn't properly explain my earlier point, but Graham did explain about punctuation.
A Visual Filter is a text Search, so it precludes punctuation.
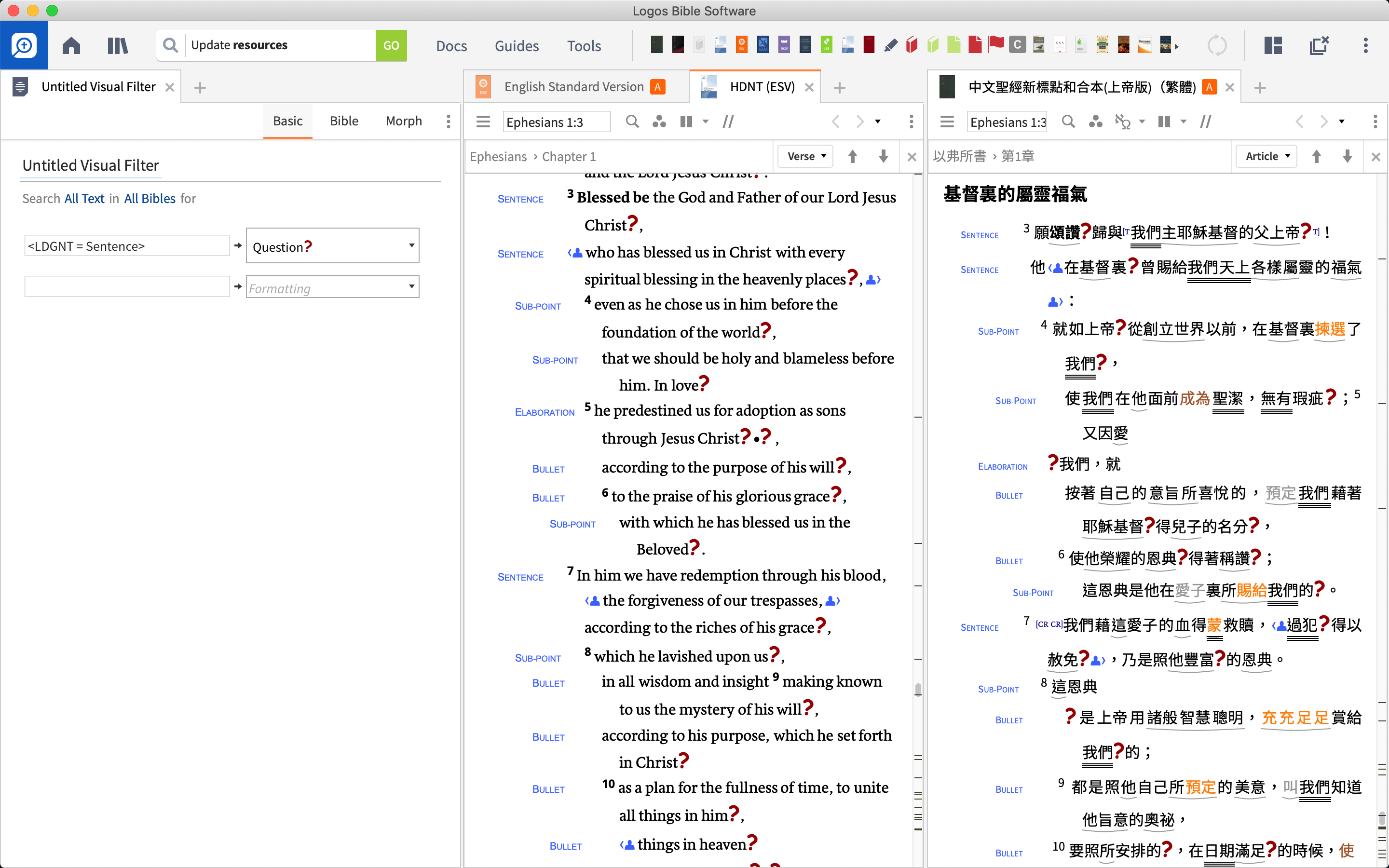
If you have any Lexham Discourse features, you would have a visual filter (Discourse features) for formatting the resource. And there is an associated Search, <LDGNT = feature> or <LDHB = feature> e.g. <LDGNT = Sentence>. The information comes from a dataset(s), but the Sentence search essentially highlights the whole resource. The Glossary is helpful, but I doubt it is significant to your need.
http://www.openculture.com/2014/07/5-very-long-literary-sentences.html ... I suspect that a clause is a universal unit that "someone's got to decide how to chop it up". I doubt that a sentence is.
For comparison:
The Guinness World Record for the longest word used in any language in the world literature is a Sanskrit word composed of 195 Devanagari characters((transliterating to 428 letters in the Roman alphabet).
The word is—
निरन्तरान्धकारित-दिगन्तर-कन्दलदमन्द-सुधारस-बिन्दु-सान्द्रतर-घनाघन-वृन्द-सन्देहकर-स्यन्दमान-मकरन्द-बिन्दु-बन्धुरतर-माकन्द-तरु-कुल-तल्प-कल्प-मृदुल-सिकता-जाल-जटिल-मूल-तल-मरुवक-मिलदलघु-लघु-लय-कलित-रमणीय-पानीय-शालिका-बालिका-करार-विन्द-गलन्तिका-गलदेला-लवङ्ग-पाटल-घनसार-कस्तूरिकातिसौरभ-मेदुर-लघुतर-मधुर-शीतलतर-सलिलधारा-निराकरिष्णु-तदीय-विमल-विलोचन-मयूख-रेखापसारित-पिपासायास-पथिक-लोकान्
In IAST transliteration:
nirantarāndhakārita-digantara-kandaladamanda-sudhārasa-bindu-sāndratara-ghanāghana-vr̥nda-sandehakara-syandamāna-makaranda-bindu-bandhuratara-mākanda-taru-kula-talpa-kalpa-mr̥dula-sikatā-jāla-jaṭila-mūla-tala-maruvaka-miladalaghu-laghu-laya-kalita-ramaṇīya-pānīya-śālikā-bālikā-karāra-vinda-galantikā-galadelā-lavaṅga-pāṭala-ghanasāra-kastūrikātisaurabha-medura-laghutara-madhura-śītalatara-saliladhārā-nirākariṣṇu-tadīya-vimala-vilocana-mayūkha-rekhāpasārita-pipāsāyāsa-pathika-lokān
This appears in a 16th-century work by Tirumalãmbã, Queen of Vijayangara.
Somehow, I think that when wishes to highlight something in the text that is arbitrarily assigned by the reader that it would be a defect to pretend that it existed in the text. The highlight belongs to the reader's brain not to the text.
It is one's interpretation to think getting the boundary between sentences are searching for period. Searching for period is one possible way to accomplish this (given the software allow one to which Logos doesn't, and given one accept the decision of that text.)
And there is an associated Search, <LDGNT = feature> or <LDHB = feature> e.g. <LDGNT = Sentence>.
Can you elaborate on this? You could just point me to a wiki article to save the time. Sounds like this is what I'm looking for.
Thanks!
Who said that a visual filter has to be reflecting what's in the text, objectively?
I always highlight books I read and I don't pretend what I highlight is "what exist in the text." The highlighting is just to help the reader to make sense out of it. And visual filter is only a glorified, automated way of manual highlighting.
And "arbitrarily assigned" is a pretty pessimistic view. One could argue whatever we try to interpret from the Bible is arbitrary. Nothing is really 100% certain, objective truth.
IMO the datasets since Logos 5 era is the most important differentiating factor of Logos from others. Manually created datasets are much better quality than automated. But no one can pretend the datasets are "God given truth" (to different extents for different kinds of datasets.) So while drawing information from there to create some sort of visual filter definitely can be "arbitrary", but one has to start from somewhere and those datasets is good enough for me. (And what are the choice other than not doing this at all?)
And there is an associated Search, <LDGNT = feature> or <LDHB = feature> e.g. <LDGNT = Sentence>. Can you elaborate on this? You could just point me to a wiki article to save the time. Sounds like this is what I'm looking for.
Found it: https://community.logos.com/forums/t/125852.aspx
It doesn't work as hoped though (Screen shot attached below.) Nice try though, especially you are the first who give it a try rather than explaining why it wouldn't work or is a bad idea.
An automated visual filter created by a computer has two options: (a) to be generated from a "random" number or (b) to be generated based on patterns recognizable by the computer which is limited to features identifiable in the text by the computer. Yes, I'm am simplifying by leaving out the possibility of using time, barometric pressure etc. as an element of selection. [:(] Remember a computer "knows" absolutely nothing but AND-NOT or OR-NOT depending on the processor.
those datasets is good enough for me. (And what are the choice other than not doing this at all?)
I have yet to buy into the datasets as anything beyond the opinion of Faithlife specifically because they sweep the ambiguities under the rug. Those ambiguities are precisely what I find fruitful to wrestle with. They are useful for learning new ways of analyzing the text ... but except for purposes of search arguments, I believe in reaching the point of competency that one can leave the datasets behind.
especially you are the first who give it a try rather than explaining why it wouldn't work or is a bad idea.
Sorry if I've come across as discouraging. I'm really only trying to help you understand what you can and cannot do conceptually, so that when you pick a way you want to do it, you'll know what you are actually looking at. Whether or not what you a looking at when you understand what it is, is entirely your choice.
Remember a computer "knows" absolutely nothing but AND-NOT or OR-NOT depending on the processor.
This statement is very strange, because computing is just to scale the logic a human assert (by programmers) to a scale unmanageable by humans. Essentially everything that can be objectively defined can be carried out by a computer, instructed by humans (programmers.)
Since we are trying to talk about something objective here (at least you're trying to restrict it to something not "arbitrary"), then whatever objective thing one want to perform can be perform by the computer, just faster in most cases.
That's very opinionated. As I said, one has to start from somewhere. Who's to say anything we obtained from using Logos are objective truth? One always needs to bear that in mind the assumptions make in the process (and for here we'd can use simply state one "trust" the quality of the dataset. No more strange than when I read a Bible and trust its translator doing a good job, or even the original Bible that the one who put them together knows what they are doing (like textual criticism stuffs.) Not having this being trust denies anyone to start from anywhere because they never can reach the level that they can independently verify whatever he's doing.
P.S. that's why I like Math and theoretical Physics because they can be reduced into axioms and principles and assumptions that one choose to believe/test/verify/falsify. So exactly where a logic breaks down can easily be traced (I glossed over the details as Science becomes very complex and requires collaboration and hence often no one single person can say they absolutely check every part of the logics and assumptions.)
May be I haven't mentioned it in the beginning, since the original scriptures doesn't even have space and punctuation so there's a degree of opinion/judgement made to say it should be grouped one way rather than the other. I don't care about that in this visual filter, as much as I don't care about what the Greek really is when I'm reading through a translation. All I care is some way somehow to provide that visual feedback, a translation that one can read much faster, to starting reading the Bible. No one would think one can obtain the ultimate objective truth when they are just reading through a Bible, which is precisely what a visual filter is about (if you want to go deep, you ain't just relying on visual filter then.)
I have a background in model theory, linguistics, natural language processing, knowledge management and am, by nature, a logician. I earned my living in programming for many decades. I am aware that this can come off as opinionated so I try to be very careful in my wording. But I have made my point as it relates to Logos and have not desire to go any further off-topic, as is my wont.
Oh, wait, on closer inspection, it works on ESV! There's some bug in CUVNP though which I'll file soon.
Thanks David Hooton! Although the sentence barrier is different from what I often was reading (e.g. Darby, LEB, etc.), but this is a starting point, and it means I don't have to manually highlighting it anymore! Should have follow closely to the release of that dataset. I have that, but never knew it can does that.
P.S. the very reason I'm using Logos right now is because its discourse bibles (like HDNT, etc.) The first ever resource I bought in Logos is actually that, rather than a library or something. i.e. it was the advance of discourse analysis from Logos that wins me over (Logos was the first, and there's only digital. Print came later.) Before that I have a whole shelf of collections and bible study requires a big table and always don't have enough space. Since then I bought a Logos 4 Scholar library and then sold my hard copy collections. I missed the feeling of taking, touching and flipping the physical books though. It was like I truly own something right before my eyes and Logos' experience is like nothing is real but just work and convenient.
Case closed!
I have a background in model theory, linguistics, natural language processing, knowledge management and am, by nature, a logician.
Made me jealous. You know, I have a passion for linguistics but got it too late. Before I believed in Christ, I wasn't interesting in languages at all (but Mathematics. I used to think Mathematics as a language is the most beautiful thing, and still do. But the Word is alive whereas Math and logic is cold and "dead".) So my foundation is weak and was too late to have any real talent in linguistics. But I just love it so much, and lately I realized language is everything. What differentiate good mathematics from the bad, mostly the language used! Mathematicians have ways to create DSL to make abstract Mathematics concrete and manageable. What differentiate good programming languages from bad ones? Language semantics again! (That's why e.g. I love Python, C, Haskell, Julia, JSON, etc. but hate Pearl, Javascript, HTML/XML, etc.) What it takes to really understand the Bible? Language again. I envy you.
But given your background, I still think your view towards what computers do and computing is might be skewed. I don't think one can truly understand and appreciate Computer Science without Mathematics. For me computer is just something that can carry out some task incredibly efficient, where all those tasks are governed by Mathematics. Being able to write program is a much more basic requirement, especially when some programming languages / paradigms is very procedural, where writing a program is no different than teaching an incredibly stupid and stubborn servant to carry out some tasks. The beauty of programming arguably lies in functional paradigm and lambda calculus, where when written probably there hardly can be any bugs (due to the guarantee from lambda calculus and requirements asserted in functional paradigm.) Sadly it isn't almighty because tasks like a GUI application as Logos are arguably more suited by Object oriented for various reasons.
But I do agree we can't trust everything from a computer. It is such a blackbox. The holy grail of computing (at least in my field) is really open source + reproducible research. I wish Logos can reach there some day but doubtful. The reason is simple, no Mathematical prove by computers will be recognized as prove unless the whole stack is open-sourced and hence open for verification. (The first computer proof on Mathematics which is the 4 colors problem is controversial because people don't want to trust a computer but we are now way past there. There are even DSL designed specifically to aid human in formal prove of very long theorem, like 400 pages long of Mathematics.)
Imagine someone claim that a particular word appears only twice in the NT, or a particular grammatical construct is unique here, how can you verify that? An indirect prove would be to perform the same search in multiple independent implementation (i.e. Logos and its competitors/friends) and verify they all gives the same result. (This is a logic often used in Applied Mathematics even some non-essential part of Pure Mathematics such as showing a huge matrix has a certain property.) But it would be that much better if there's a program/notebook one can reproducibly run and point out to people, "run this and you will found this too."
That's partly why I think Logos should have a better API to interface with it. There's no escape in Biblical research that we relies on a certain dataset that is not free (even NA28 is some form of a dataset that computer can act upon.) But if the programming logic is deferred to a programming language, one can make it available (i.e. open source) and say, "hey, if you have that Logos dataset/database you can independently verify that by running my script/notebook."
But I also understand the Christian culture is very different from that of scientific community. But also think this: if someone want to give away their sources that one can freely evaluated (open source and copyright is 2 independent concept), shouldn't Christian be one of the proponents in doing so and say "hey, look! Truth here feel free to inspect!"
Probably I digress too much so let me just suddenly stop
But given your background, I still think your view towards what computers do and computing is might be skewed.
It is also skewed by an observation of years of small group Bible study. Many Christians practice Bible study in a way that they fill their allocated study time in a way that allows them to check the box of "Bible study" but in a way that makes sure they never actually have to learn anything new in the sense that Peter Enns presents. From the Amazon blurb on How the Bible Actually Works: In Which I Explain How An Ancient, Ambiguous, and Diverse Book Leads Us to Wisdom Rather Than Answers—and Why That’s Great News which was recently requested in the forums.
[quote]How the Bible Actually Works makes clear that there is no one right way to read the Bible. Moving us beyond the damaging idea that “being right” is the most important measure of faith, Enns’s freeing approach to Bible study helps us to instead focus on pursuing enlightenment and building our relationship with God—which is exactly what the Bible was designed to do.
The result is that I firmly believe in asking how will this technique/method/skill help me to reach my goal which may be as diverse as:
PS. I know nothing about Peter Enns beyond the Amazon page and the forum thread ... this is not an endorsement of him.
It might be skewed by:
I think the feeling of your skewness really just come from this statement
This statement is just so wrong on many different levels. It is more wrong on what one assumes and want imply than the statement itself is. With this skewed view of what computer does there's almost a certain phobia of computer implied.
...makes clear that there is no one right way to read the Bible. Moving us beyond the damaging idea that “being right” is the most important measure of faith
Don't know the underlying philosophy here, but my believe is that there's objective truth and that should be the goal to seek, but at the same time it is unattainable such that anyone claiming theirs are the objective truth is subjective. The process of truth seeking is iterative refinement, one gets closer (sometimes spiral around or occasionally further away) but never attains. i.e. it is like an infinite series where taking the limit would be the result, but each term one obtain never equals to the limit. (A more accurate analogy may be a Cauchy sequence.) IMHO without such believe it is pointless to pursue things such as faith or science, but may be arts, etc. where everything can be relative.
May be his emphasis is more on "ways" rather than right though. Interpreted this way, it is more like "All roads lead to Rome". This idea can be dangerous though. Another analogy, some photographers tends to claim that there's no right way to take pictures and it's just different styles. They used this argument as a license to not learn proper techniques to do things right. So I also hold the believe that while sometimes there's "no right way" to do something, there exists wrong ways to do something. There aren't objective best kind of photography, but there are objective "garbage" kind of photography.
It is also skewed by an observation of years of small group Bible study. Many Christians practice Bible study in a way that they fill their allocated study time in a way that allows them to check the box of "Bible study" but in a way that makes sure they never actually have to learn anything new...
That's sad to hear. That's what I missed from the Church of Hong Kong and I now wonder if the majority of US churches are like this. But it seems that majority of Logos users wouldn't be like this though. Or is it?