I created a Personal Book from a class I took this semester on the Acts of the Apostles. The professor's class notes used the European format for citing the Bible, where it is common to say Acts 1,1 instead of Acts 1:1.
Given that Logos Personal Books don't understand this format, I found myself with the difficulty of trying to replace all the commas with semicolons. Luckily with Microsoft Word this is extremely easy.
I told Microsoft Word to search for every occurrence of "a number followed by a comma followed by a number" and replace it with the same numbers, but with a semicolon in between.
Here is what the search looks like. Notice that the "Use Wildcards" option is selected.
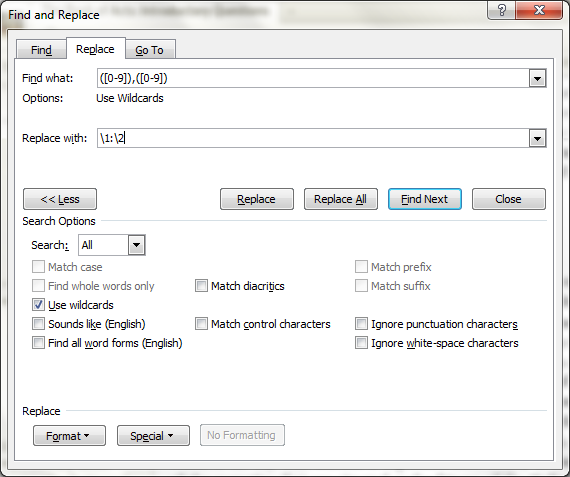
There is documentation on doing this type of search and replace here: http://office.microsoft.com/en-us/word-help/find-and-replace-text-by-using-regular-expressions-advanced-HA102350661.aspx
This technique can also be used to insert the codes which Personal Books need to indicate that a certain heading is, for example, a Dictionary Head Word. If all the head words in your dictionary have the same formatting, in just a matter of a few minutes of work you could apply the information that the Logos Personal Book needs to recognize 1000s of head words.

























